I do research in the areas of machine learning and data visualization. I'm currently interested in interpretability and control of deep neural networks, in order to enable new ways to understand and interact with AI systems.
Publications







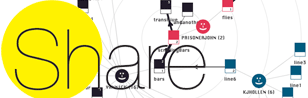
M.S. Thesis (2009) | CHI 2010
Share
Advisor: Dr. Judith Donath
A networked programming environment that tracked and visualized code reuse within a community of artist-programmers.
Projects

A podcast in which a writer and a software engineer explore the human choices that shape machine learning systems. (2020)


Visual essay using machine learning and neural networks to explore visual motifs in Wes Anderson films. (2017)

An experiment with the Quick Draw! dataset that uses Principal Component Analysis to explore variation in hand-drawn doodles. (2017)

Network-themed visualization of conference talks from OpenVis. Speakers are connected by transcript similarity and tag groups. (2017)

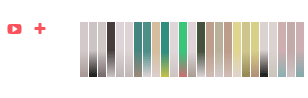
Visualization of conference talks from OpenVis. Dominant colors in speaker slides extracted to form basis of the visualization. (2014)

A quick sketch in creating a playful way to examine various features of your Twitter stream. (2010)
Art

Art installation. Done in collaboration with the MIT Media Lab Sociable Media Group. Watch Video (2009)

Dynamic typeface whose form and evolution is parameterized by your voice. (2007)

Site-specific art installation on the topic of extraordinary rendition. Installed for over a year in Toronto's Pearson International Airport. (2007)



Cellular Automata + Granular Synthesis. Max/MSP based tool for granular re-synthesis of audio. (2005)